Spring Integration - Bulk processing Example
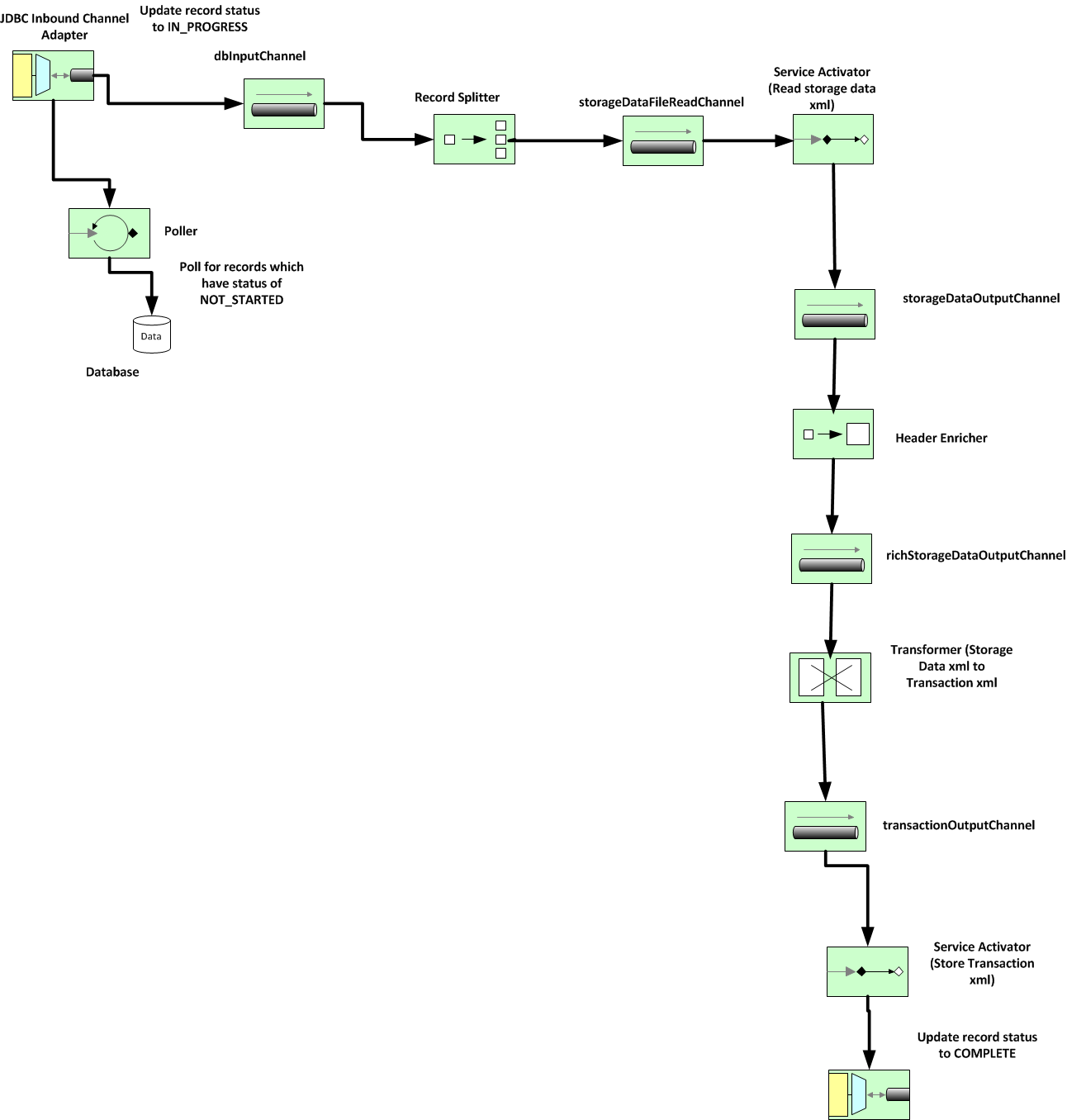
In this post, I'm going to share my experience in using Spring Integration for a bulk processing task. This was the first time I was using Spring Integration and it did not disappoint me. It was pretty robust in terms of error handling and definitely scalable. Disclaimer: The actual task being performed has been modified into a fictitious e – commerce domain task, since I cannot reveal the original task which is customer specific and confidential. However, the nature of the task in terms of processing of clob and xml remain the same and the complexity of the original task has been retained. Also, the views posted on this post are strictly personal. Objective: The objective is to work upon customer information from an ecommerce application and process it and save it into database as clob data. The task is to perform data processing by reading xml from a file in the file system and then store it as clob into a table. Following is the high level of tasks required t